
В Discord-е AP-PRO вновь появился бот! Я уже далеко не в первый раз делаю бота для AP-PRO. Первые 2 версии были сделаны для Telegram и не отличались особенным качеством по сравнению с текущим. Так же была версия для Discord-а, однако она технически устарела, из-за чего я решил переписать её, используя знания, которые я получил во время работы над языковым расширением для VSCode (подробнее тут). Время описать нововведения.
Новая реализация команд
Как я писал выше, я уже делал бота и он технически устарел. Ранее, для использования команд, было нужно указывать уникальный префикс и вручную писать название команды. Сейчас же команды встроены в Discord и грамотно оформлены:
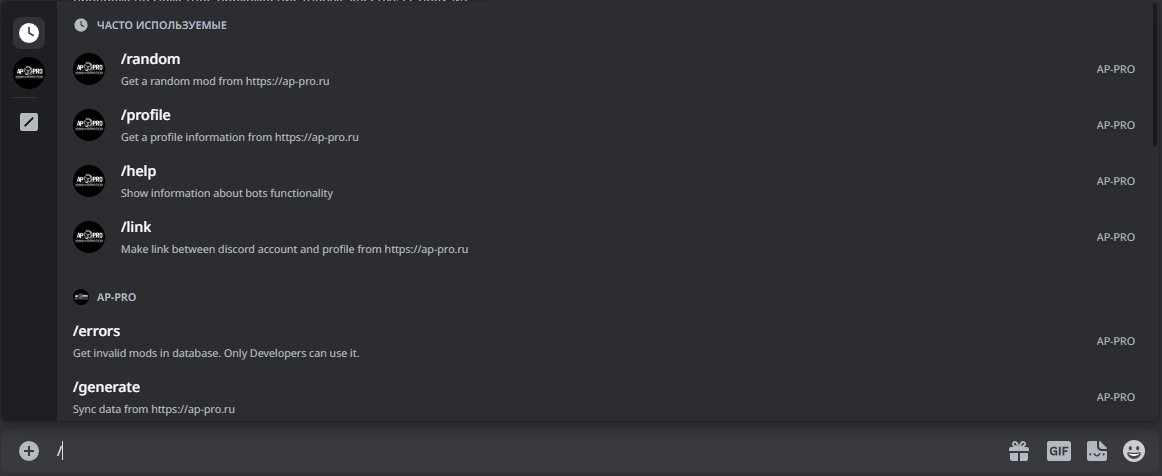
Префикс для всех ботов стал общим, команды хранятся в виде списка, при том, с наличием возможных аргументов и описания. То есть, если раньше о функционале бота можно было даже не догадываться, то сейчас же пропустить что-то стало затруднительно.
Новый алгоритм сбора информации
Начнем с того, что бот умеет собирать информацию с сайта и хранить её для отображения в Discord-е. На этом и основывались все версии бота. Он "парсит" страницу и после сохраняет в базе данных информацию с неё, для того чтобы сделать работу легче, быстрее и не добавлять лишней нагрузки сайту. Однако, с открытием мною асинхронности, это больше не является такой сильной проблемой. Для начала, достаточно сравнить скорость сбора информации обоих алгоритмов:
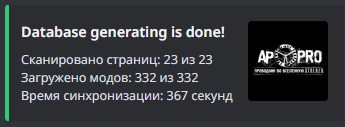
- Старый алгоритм:
- Новый алгоритм с асинхронностью:
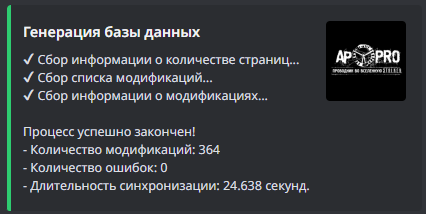
Самое интересное, что таких показателей со старым алгоритмом можно было добиться только при условии, что бот пропускал записи, которые уже были в базе данных, то есть, сбор только новой информации.
Однако, у данного алгоритма есть проблема. Мне до конца не ясно, из-за чего это происходит, однако иногда бот просто не может получить страницу, даже спустя несколько попыток. Я предполагаю, что алгоритм работает настолько быстро, что срабатывает некоторая защита, которая мешает получить страницу. К сожалению, проверить или исправить у меня это не вышло, поэтому я просто сохраняю информацию о том, что именно не вышло получить и надеюсь решить это в будущем.
Фильтры для модификаций
Раньше бот выдавал игроку случайную модификацию при вызове команды "?random". Если же он хотел случайный мод на определённой платформе, то использовал команды: "?random_soc", "?random_cs" или "?random_cop". Как можно догадаться, и со стороны разработчика и со стороны пользователя это было неудобно. Однако сейчас, с появлением полноценной поддержки аргументов, можно ограничиться лишь командой "/random", где, при желании, можно указать желаемую часть игры.
Однако, зачем останавливаться на этом? Я тоже спросил себя об этом, и после некоторых манипуляций с кодом добавил еще несколько фильтров, количество которых я планирую увеличить. На данный момент, можно отфильтровать моды по таким параметрам:
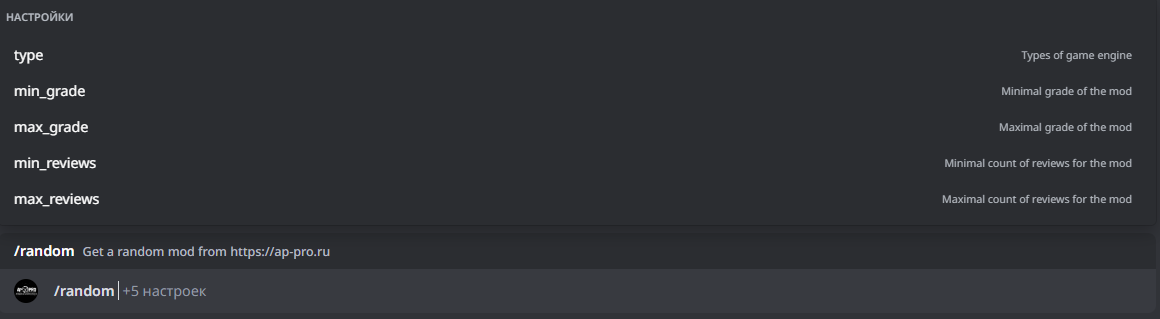
- Часть из трилогии
- Минимальная средняя оценка
- Максимальная средняя оценка
- Минимальное количество отзывов
- Максимальное количество отзывов
Всё из перечисленного является опциональный. Небольшой список, однако я планирую сделать его больше, добавив:
- Минимальный год релиза
- Максимальный год релиза
- Наличие определённого тега у модификации
- Наличие отзыва у пользователя (при подключённом профиле)
По сути, ничего невероятного, однако именно для этих параметров нужно произвести некоторые манипуляции кода, что будет уже в следующих обновлениях.
Код, переписанный практически полностью
Не столько нововведения для пользователей, сколько лично для меня. Так как я переписывал бота с нуля, я брал некоторые готовые вещи из старой версии, которые в последствии переделывал. И скажу так, код был просто ужасен.
Например, код получения информации со страницы пользователя в старой версии занимал около 90 строк и выглядит он так:
def sync_info(self): page = requests.get(self.url) page_tree = html.fromstring(page.content) try: nick = page_tree.xpath('//*[@id="elProfileHeader"]/div[2]/div[2]/div/h1/text()') self.nick = nick[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.nick = "Ошибка, пиши админу" try: reputation = page_tree.xpath('//*[@id="elProfileInfoColumn"]/div/div[2]/a/div/span[1]/text()') or page_tree.xpath('/html/body/main/div/div/div/div[1]/div/div/div/div/div[1]/a/div/span[1]/text()') self.reputation = reputation[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.reputation = None try: posts = page_tree.xpath('//*[@id="elProfileStats"]/ul/li[1]/text()[last()]') self.posts = posts[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.posts = None try: group = page_tree.xpath('//*[@id="elProfileHeader"]/div[2]/div[2]/div/span/span/text()') self.group = group[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.group = None try: date = page_tree.xpath('//*[@id="elProfileStats"]/ul/li[2]/time/text()') self.date = date[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.date = None try: reputation_leaders = page_tree.xpath('//*[@id="elProfileStats"]/ul/li[4]/span/text()') self.reputation_leaders = reputation_leaders[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.reputation_leaders = None try: self.contacts = get_contacts_from_url(page_tree = page_tree) except: self.contacts = None try: rewards_page = requests.get(self.url + "/?tab=node_awards_Awards") rewards_page_tree = html.fromstring(rewards_page.content) self.rewards = rewards_page_tree.xpath('//*[@id="ipsTabs_elProfileTabs_elProfileTab_node_awards_Awards_panel"]/div/div[@class="ipsResponsive_showDesktop ipsResponsive_block"]/div/div[2]/h2/text()') except: self.rewards = None try: img_url = page_tree.xpath('//*[@id="elProfileHeader"]/div[1]/img/@data-src') self.img_url = img_url[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.img_url = None try: avatar = page_tree.xpath('//*[@id="elProfilePhoto"]/a[1]/img/@src') self.avatar = avatar[0].encode('raw-unicode-escape').decode('utf-8').strip() except: self.avatar = None try: self.reviews = [] count = get_page_count_of_articles(self.url) if count: if count != 1: for i in range(count): if i != 0: get_user_reviews(self.url, i, self.reviews) else: get_user_reviews(self.url, count, self.reviews) except: self.reviews = None if "--devmode" in sys.argv: print(self.nick) print(self.reputation) print(self.posts) print(self.img_url) print(self.avatar)
В новой же - 36 строк и выглядит это так:
async def getUserInfo(url: str, user: str, id: int) -> Profile: address = f'{url}/profile/{user}' result = dict(id=id, url=user) async with aiohttp.ClientSession() as session: counter = 0 resp = await session.get(address) while resp.status != 200 and counter < 5: if resp.status != 200: resp.close() counter += 1 await asyncio.sleep(2) resp = await session.get(address) if resp.status != 200: resp.close() result['valid']=False _log.error(f"Can`t get {url}. Code: {resp.status}. Reason: {resp.reason}") return Profile(result) page_tree = html.fromstring(await resp.text()) for item in infoList: data = page_tree.xpath(item[1]) if data == []: _log.warning(f"Can`t find {item[0]} for {url}. Get: {data}") result[item[0]] = "" continue data = data[0].strip() if len(item) > 2: data = item[2](data) result[item[0]] = data resp.close() _log.debug(f"Get data from {url}") profile = Profile.parse_obj(result) profile.contacts = await getUserContacts(url, user) return profile
Можете сказать, что это ничего особенного. Однако это разница с учётом того, что именно происходит в данном коде. Думаю, те кто хоть немного разбираются в программировании, понимают, что один код выгляди намного лучше второго, по многим причинам:
- Чтобы добавить новые данные, необходимо редактировать исходный код класса, в то время как в новой версии достаточно просто добавить новый пункт в массиве. Это легче и быстрее.
- Убраны бессмысленное повторение кода, которое идентично для всех параметров
- Масштабировать функционал проще
- Код банально выглядит чище и легче
Кончено же, до идеала тут далеко, множество вещей мне предстоит выучить и исправить, но мне приятно наблюдать за тем, как я становлюсь лучше.
На этом всё. Спасибо за внимание! Надеюсь, что данную статью было интересно почитать. Если кто-то имеет рекомендации по улучшению или идеи, которые бы хотелось увидеть - пишите. А если вас заинтересовал бот и вы хотите его лично опробовать, то он доступен в Discord-е, по этой ссылке, в канале #bot-ap-pro: Ссылка
-
 7
7
-
.png) 1
1










2 Комментария
Рекомендуемые комментарии
Для публикации сообщений создайте учётную запись или авторизуйтесь
Вы должны быть пользователем, чтобы оставить комментарий
Создать учетную запись
Зарегистрируйте новую учётную запись в нашем сообществе. Это очень просто!
Регистрация нового пользователяВойти
Уже есть аккаунт? Войти в систему.
Войти